
FreeOCR
5.4.1
Size: 10.8 MB
Downloads: 4698
Platform: Windows (All Versions)

OCR is short for optical character recognition, the technology that analyzes an image, recognizes text in the image, and extracts said text so that you can edit it or use it in other ways. A simple example of OCR technology at work is when you snap a picture of some text with Google Translate and the app translates said text into any language you want.
FreeOCR puts such technology at your disposal without asking for your hard earned money in return. You can load scanned images into the application, other types of images, and PDF files as well. The application will use OCR to identify, extract, and deliver the text to you. It uses the Tesseract OCR engine to offer this type of functionality to you.
The minimum system requirements for running FreeOCR are: 1GB of RAM memory, 20MB of free disk space, SVGC resolution display, .NET Framework 2.0 or higher, Windows operating system (anything from Windows XP SP2 up to Windows 8 for the desktop). A simple setup wizard will help you get FreeOCR up and running on your Windows-powered machine. Please note that it will ask to install some additional software: Mixi DJ Toolbar and RegClean Pro. Opt out if you don’t want these extra software applications.
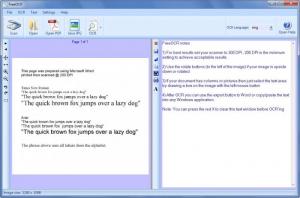
The FreeOCR interface is divided into two panels: the one to the left presents the file you loaded into the application; and the one to the right displays the text extracted from the aforementioned file. To help you get started, these two panels are pre-populated. The one to the left presents a sample scanned image. And the one to the right presents some useful notes on how to use FreeOCR.
There’s nothing complicated about using FreeOCR. It is, as a matter of fact, a simple 3-step process:
Step 1 – load a file into the application. You can import a scanned image, load an image file, or open a PDF file.
Step 2 – choose if you want to process all the pages or just one page from the file you loaded. It must be added here that the OCR technology provides support for multiple languages.
Step 3 – do whatever you want with the text FreeOCR extracted. You can edit it, copy it to the clipboard and paste it into any application you want, export it to Microsoft Word, and export it as RTF.
As mentioned above, and as it’s obvious from its name, FreeOCR is free software.
Extract text from images, scans, or PDF files and do whatever you want with it. You can efficiently do so for free with FreeOCR.
Pros
The system requirements for running FreeOCR are quite low. FreeOCR uses the Tesseract OCR engine, an open source product released by Google. Useful information on how to use the application is clearly displayed on the user friendly interface. You can process just one page or all pages. Support for multiple languages is provided. You can copy text to the clipboard, export it to Word or RTF. FreeOCR is free software.
Cons
The setup wizard wants to install some additional software.
FreeOCR
5.4.1
Download
FreeOCR Awards

FreeOCR Editor’s Review Rating
FreeOCR has been reviewed by George Norman on 16 Jul 2013. Based on the user interface, features and complexity, Findmysoft has rated FreeOCR 5 out of 5 stars, naming it Essential
























